|
Tutorial on SDL-88 Belina, Hogrefe (edits Reed) |

|
|
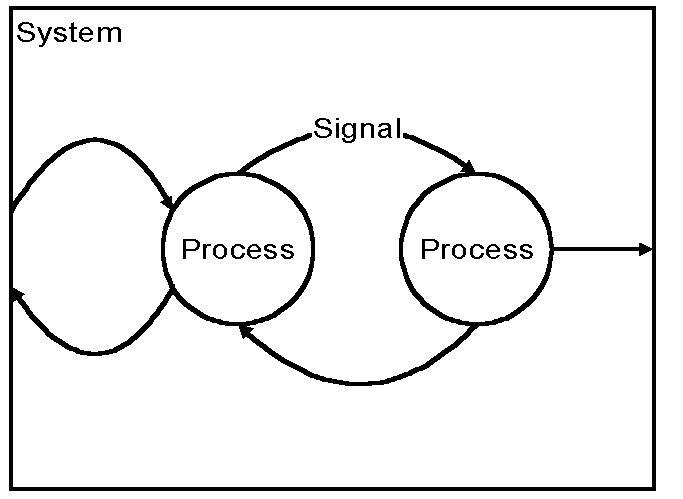
The language is described in this tutorial on three levels. This section gives a first level of description, to give the reader a general overview before getting into more details in the second level description. The second level description is given in §2 - §8. The third level description in §9 - §10 gives a more thorough explanation of the basic concepts, and is intended for a more advanced reader. Note: This tutorial is not a text book on SDL-88. It gives only an introduction, and does not provide a complete treatment. Consult the language definition Z.100 [1] for the complete description of the language. Consult a text book for a more complete tutorial. Definition, type and instanceFor most basic concepts a clear distinction is made between definition, type and instance. The definition defines the type. From a given type a desired number of instances can be created. If we take (for example) the system concept, then a description of a system (a system definition) can be compared to a source program. Note: A system instance of a specification is usually only an imaginary object: it is not created or built as a real system, but it can be simulated. For practical reasons the term instance is usually omitted in the following. For example the term system means system instance, if not stated otherwise. Note that in the language syntax the term definition is used as a neutral term instead of the term specification or description. System behaviourThe behaviour of a system is constituted by the combined behaviour of a number of processes in the system, see figure 1 below. A process is an extended finite state machine, that works autonomously and concurrently with other processes. The co-operation between the processes is performed asynchronously by discrete messages, called signals. A process can also send a signals to and receive signals from the environment of the system. It is assumed that the environment acts in the same way as the Specification and Description Language, and it obeys the constraints given by the system description, in particular it only sends signals to the system that are defined on the interface with the environment. The behaviour of a process is deterministic: it reacts to external stimuli (in the form of signals) in accordance with its description. Each process has a unique identity (of the predefined type Pid). A signal always carries the identity of the sending and the receiving process, in addition to possible data values. The receiving process thus always knows the identity of the sending process. A process has a memory of its own for the storage of variables (in addition to the state information, which is not directly accessible to a user creating the model). A process cannot write into the variables of another process even if it is an instance of the same process. Note: In SDL-88 there is actually a mechanism for directly accessing the variables of another process, but its use is deprecated as it is unsafe because actual behaviour can be unpredictable. In SDL-2000 direct access is allowed between non-concurrent processes to shared data. A process has a theoretically infinite input queue, where incoming signals are queued. A process is either in a state waiting for a signal, or is performing a transition between two states. A transition is initiated by the first signal in the input queue that the process accepts in that state. When a signal has initiated a transition, it is removed from the input queue (and is said to be consumed). In a transition, variables can be manipulate, decisions can be made, new process can be created, signals can be sent (to other processes or to the process itself) etc.
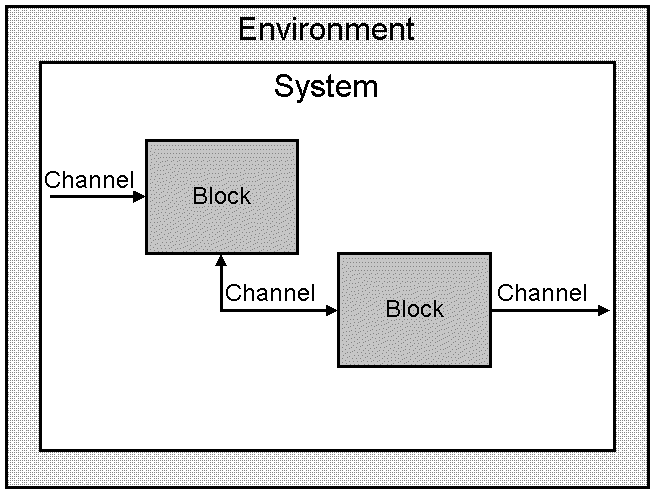
Figure 1: System behaviour System structureThe aim of structuring is to cope with complexity. The process concept is suitable also for structuring, but a process in SDL-88 is always be contained in a block, which is the main structuring concept. A system contains one or more blocks, interconnected with each other and with the boundary of the system by channels. A channel is a means of conveying signals. See figure 2.
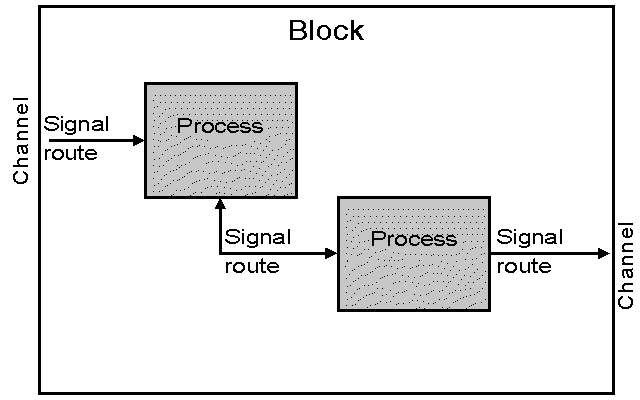
Figure 2: Static structure of an SDL system A block can be partitioned into (sub)blocks and channels, similar to the partitioning of the system according to figure 2. In fact, a system can be regarded as a special kind of block, having no channels connected to it from the outside. Blocks within a block are interconnected with each other and with the boundary of the enclosing block by channels. Repeated block partitioning results in a block tree structure (with the system as the root block). In SDL-88 a partitioned block (that is a block containing blocks) does not directly contain any processes. A leaf-block of a block tree structure in SDL-88 is not partitioned, and contains processes. Each process shown in a leaf block diagram has a different definition. Within a leaf-block, signals are conveyed on signal routes between processes, and between a process and the boundary of the block (a signal route is analogous to a channel), see figure 3.
Figure 3: Structuring a block into process types The static structure of a system is, of course, reflected in its description. In SDL-88 a block description can contain both process descriptions (corresponding to a leaf-block) and a block structure description (corresponding to a partitioned block). The choice between these two versions of a block must be made before interpretation time (the result is called consistent portioning subset) - see "System interpretation". However, having two (or more) alternative descriptions for the same block was not found to be very useful and somewhat confusing, so this feature was dropped in SDL-2000. Abstract dataTo define data, the axiomatic abstract data type approach has been chosen. That means that all data types (predefined as well as user defined) are defined in an implementation independent way, only in terms of their properties. The definition of an abstract data type by axioms has three components:
It is also possible to derive a data type from other already defined data types. It has been considered desirable to provide some predefined data types in the language (although this is not absolutely necessary), which are familiar in both their behaviour and syntax, for example Integer, Boolean, Character, Array. Note: The language actually makes a distinction between data type and sort (the set of values of Integer, Character etc. are sorts). The distinction is explained in "Data type concepts", but is usually omitted in other chapters. The axiomatic abstract data type approach differs substantially from the usual approach in programming languages, where a user has to define a new data type by means of already defined data types, and ultimately by means of the predefined data types of the language. This constructive approach used in programming languages can imply undesirable restrictions and a particular implementation. On the other hand, defining well-formed abstract data types using axioms is not easy, and it is difficult to directly implement or simulate such definitions. For this reason it is suggested to avoid writing axioms and use the built-in data types. When extra operations are required, it is suggested to define these with operator algorithms given textually or in operator diagrams. In SDL-2000, while all the built-in data types are still abstract data types defined using axioms, it is not allowed to add axiomatic descriptions to the language model: any user defined data types have to be constructed from existing ones and algorithmic operator descriptions. Representation formsThe user friendliness of SDL-88 is partly due to the graphical representation, SDL/GR, in which graphical syntax is used to give an overview. This is complemented by textual syntax for some concepts, where graphical symbols are unsuitable: for example, data types. There is also a textual phrase representation, SDL/PR, that uses only textual syntax. SDL/GR and SDL/PR have a common subset of textual syntax, and thus overlap each other. SDL/PR is used mainly for communication between tools.
|
|
Contact the webmaster with
questions or comments about this web site. |